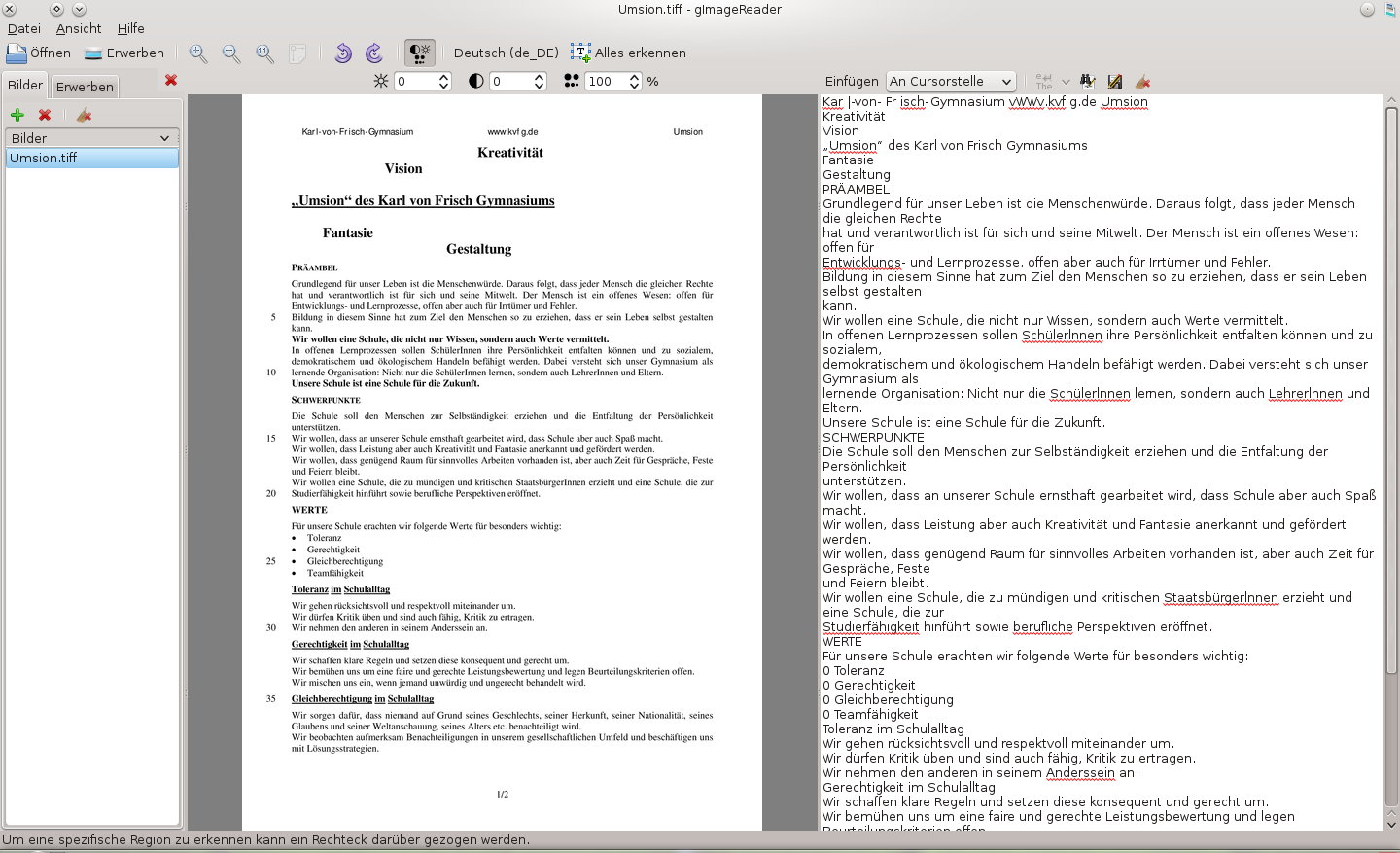
Politiklehrer brauchen Zeitungsausschnitte wie ein Fisch das Wasser. Ideal ist es, wenn diese noch mit Zeilennummern versehen und um unnütze Details gekürzt werden können. Hierzu setze ich OCR Software ein – leider in einer virtuellen Maschine, weil Linux sich hier von seiner spröden Seite zeigt (siehe: OCR unter Linux).
Einen Scan des lesenswerten Artikels ‚Die Unsicherheitskrise‚ von Stefan Kornelius aus der SZ vom 7./8.02.2009 (p. 4) nahm ich zur Vorlage, um die Qualität verschiedener Online-OCR-Dienste zu testen (mit freundlicher Genehmigung der SZ). Dabei wurde darauf verzichtet, die Dienste mit mehrspaltigem Layout und eingebetteten Bildern zu foltern. Dafür war aber die Scanqualität an sich nicht gerade rosig.
tohoku
http://ocr1.sc.isc.tohoku.ac.jp/e1/
Ein Staat geht hr die Sicherheit sei-
ner Bürger drei Verpflichtungen ein: Er
schützt mit seinem Militär vor einem äu-
Qeren Feind, er sor& rr_t der Polúei für
SicherheitiInInneren, und erbetreibt ei-
ne uIwichtige Wirtschaftspolitik, die vor
ökonomischer Unsicherheit schützen
soll. Erstaunlich nw, dass der Zusam-
memang zwischen der ökonomischen
Knse und der physisclien Sicherheit, der
UnverseMheit der Bürger von Riga bis
Sh h . S_ p lobisSacramen
Ich behaupte, dass hier GOCR im Hintergrund läuft – zumindest erinnert mich die schlechte Erkennungsleistung stark an dieses Programm. Ich habe es zwar nicht ausprobiert, aber die Nachbearbeitung dürfte in diesem Fall fast so viel Zeit brauchen wie das Abtippen.
my.ocrnow
https://my.ocrnow.com
Ein Staat geht für die Sicherheit seiner Bürger drei Verpflichtungen ein: Er schützt mit seinem Militär vor einem äußeren Feind, er sorgt mit der Polizei für Sicherheit im Inneren, und er betreibt eine umsichtige Wirtschaftspolitik, die vor ökonomischer Unsicherheit schützen soll. Erstaunlich nur, dass der Zusammenhang zwischen der ökonomischen Krise und der physischen Sicherheit, der Unversehrtheit der Bürger von Riga bis Shanghai, von Säo Paulo bis Sacramen-to
Keine schlechte Erkennungsleistung für einen kostenlosen Service, der lediglich eine Registrierung voraussetzt. Fortgeschrittene Funktionen sind kostenpflichtig und beinhalten das Zusenden des fertigen OCRs und die Einreichung per Mail.
iupr
http://demo.iupr.org/cgi-bin/main.cgi
Ein Staat geht fiir die Sicherheit sei
ner Burger drei Verpflichtungen ein: Er schiitzt mit seinem Militar vor einem auBeren Feind, er sorgt mit der Polizei fiir Sicherheit im Inneren, und er betreibt eine iunsichtige Wirtschaftspolitik, die vor okonomischer Unsicherheit schiitzen soll. Erstaunlich nur, dass der Zusammenhang zwischen der okonomischen Krise und der physischen Sicherheit, der Unversehrtheit der Burger von Riga bis Shanghai, von S50 Paulo bis Sacramen- ‚ ` ‚ “ i’Dl€1H‘Is€°
Schon besser als tohoku – aber auch nur, weil die Fehler auf den ersten Blick zu sehen sind. An den besser erkennbaren Bildstellen (also nicht am Falz in der Zeitung) ist die Erkennungsleistung ordentlich.
ocrterminal
http://www.ocrterminal.com
Ein Staat geht fur die Sicherheit seiner Burger drei Verpflichtungen ein: Er schutzt mit seinem Militar vor einem au-Beren Feind, er sorgt mit der Polizei fur Sicherheit im Inneren, und er betreibt eine umsichtige Wirtschaftspolitik, die vor okonomischer Unsicherheit schutzen soil. Erstaunlich nur, dass der Zusam-menhang zwischen der okonomischen Krise und der physischen Sicherheit, der Unversehrtheit der Burger von Riga bis Shanghai, von Sao Paulo bis Sacramento
Saubere Erkennungsleistung auf dem Niveau von my.ocrnow. Die Seite bietet ihre Dienste kostenlos an, erlaubt aber „nur“ 30 Seiten am Tag, was für den Alltag wohl völlig ausreichend sein dürfte.
Fazit
Die Ergebnisse waren recht eindeutig: my.ocrnow oder ocrterminal können weiter empfohlen werden. Standalone Anwendungen wie FineReader oder Omnipage schlagen diese Services aber um Längen in der Erkennungsleistung (bezogen auf den Gesamtartikel), sind schneller, arbeiten sich auch durch umfangreiche Dokumentenstapel und beschweren sich nicht, wenn sie mit mehrspaltigem Layout konfrontiert werden.
Für anspruchsvollere OCR-Jobs führt demnach kein Weg an Programmen wie FineReader und Omnipage vorbei, aber für den schnellen Scan zwischendurch und auch für kurze Artikel reicht inzwischen ein Online-OCR. Unter Linux sind diese bei unter einer Seite Textumfang wohl auch schneller zu nutzen als der Start der virtuellen Maschine an Zeit braucht.