
Der Stundeplanrechner wirft die WebUntis HTML Dateien in ein WebDAVs Share. Dieses ist auf dem Moodle Server per Symlink in das Arbeitsverzeichnis des folgenden untisparser Skriptes eingebunden. Von dort wird das Ergebnis in ein File Repository des Lehrermoodles geschrieben und aus dem Kursraum „Schwarzes Brett“ (die Kommunikationsplattform der Schule) verlinkt. Das stellt sicher, dass nur Menschen, die a) am Moodle angemeldet und b) Mitglied des entsprechenden Kursraumes sind den Inhalt (hier: Vertretungsplan) einsehen können.
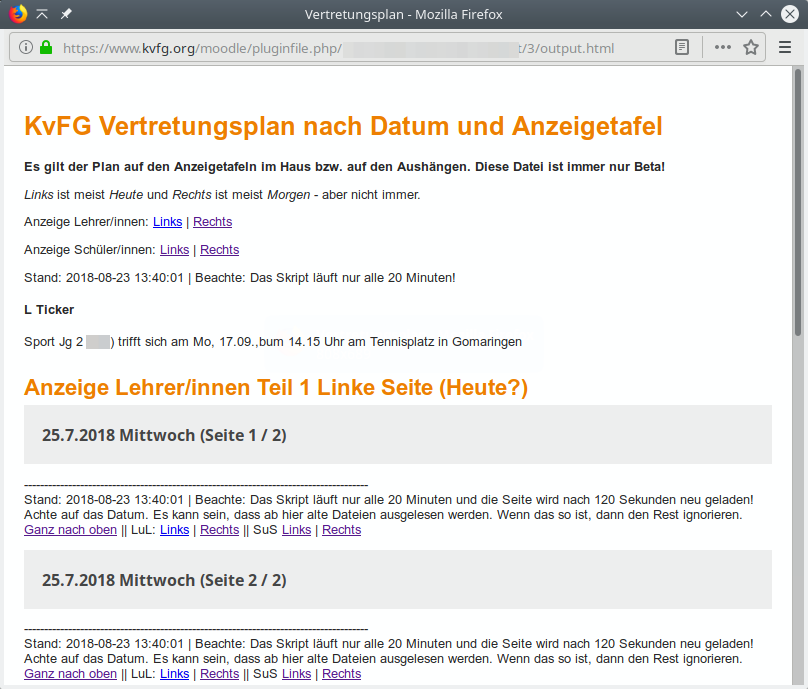
Mit geschlossenem Accordion

Accordion offen
Das muss leider so umständlich sein, weil ich keinen Weg gefunden habe, den WebDavs Ordner als solchen navigierbar im Kursraum so einzubinden, dass man diesen nicht auch von außerhalb des Moodles aufrufen könnte. Mir bleibt (sofern ich richtig liege) nix anderes über, als aus den X html Dateien, die WebUntis mir hinwirft, eine einzige zu bauen, die ich klar benamen und dann „verlinken“ kann. Dazu muss ich die vielen WebUntis HTML Dateien in ihre Bestandteile zerlegen. Ich brauche: Die Tabellen und die Zeitangaben.
Im Prinzip geht das mit beautifulsoup und Python. Meine Python-Kenntnisse sind jedoch leider noch rudimentärer als meine Bash-Kenntnisse … also muss ein bash Skript her. Und HTML mit Bash nativ parsen – nun: ich weiß, dass das Probleme macht. Das will man nicht.
Die Lösung ist pup, das ich in ein Bash-Skript einbinde.
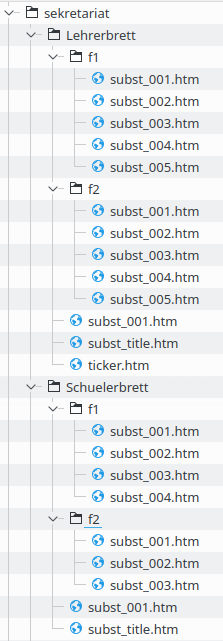
Zur Information die Struktur der WebUntis Dateien in ihren Ordnern / Unterordnern:
Die zu erzeugende Output-Datei soll HTML sein und braucht dazu einen Kopf:
<html>
<head>
<title>Vertretungsplan</title>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
<meta http-equiv="cache-control" content="max-age=0" />
<meta http-equiv="cache-control" content="no-cache" />
<meta http-equiv="expires" content="0">
<meta http-equiv="pragma" content="no-cache" />
<meta http-equiv="refresh" content="120" />
<style type="text/css">
body { margin-top: 20px; margin-left: 20px; margin-right: 20px;
background: #fff; color: #272727; font: 80% Arial, Helvetica, sans-serif; }
h1 { color: #ee7f00; font-size: 200%; font-weight: bold;}
h2 { color: #ee7f00; font-size: 175%;}
h1, h2 { margin: 0; padding: 25px 0px 5px 0px;}
/* put your css here or copy from untishtml */
/* Style the buttons that are used to open and close the accordion panel */
.accordion {
background-color: #eee;
color: #444;
cursor: pointer;
padding: 18px;
width: 100%;
text-align: left;
border: none;
outline: none;
transition: 0.4s;
}
/* Add a background color to the button if it is clicked on (add the .active class with JS), and when you move the mouse over it (hover) */
.active, .accordion:hover {
background-color: #ccc;
}
/* Style the accordion panel. Note: hidden by default */
.panel {
padding: 0 18px;
background-color: white;
display: none;
overflow: hidden;
}
</style>
</head>
<body>
<script>
window.onload=function(){
var acc = document.getElementsByClassName("accordion");
for (var i = 0; i < acc.length; i++) {
acc[i].addEventListener("click", function() {
this.classList.toggle("active");
var panel = this.nextElementSibling;
if (panel.style.display === "block") {
panel.style.display = "none";
} else {
panel.style.display = "block";
}
});
}
};
</script>
<h1>KvFG Vertretungsplan nach Datum und Anzeigetafel</h1>
<p><strong>Es gilt der Plan auf den Anzeigetafeln im Haus bzw. auf den Aushängen. Diese Datei ist immer nur Beta!</strong></p>
Siehe zum Code für das Accordion im Kopf und im „Kleister“: https://www.w3schools.com/howto/howto_js_accordion.asp Leider hat das aber nicht gereicht. Zuerst muss gewartet werden, bis die gesamte Seite geladen ist, dann erst darf die for-Schleife beginnen. Also wird das Skript in den Footer gelegt oder gekapselt in:
window.onload=function(){
... }
/* thanx Janis for debugging */
Was einen Kopf hat, braucht auch einen Fuß:
<p></p> <p>----</p> <p>(C) dowel 2018 | UntisParser Version 0.1</p> <p>Fehler sind immer möglich und sollten <a href="https://yourschoolsbugtracker.tld" target="_blank">im Bugtracker gemeldet werden</a>, damit diese behoben werden können. Wer keinen Bugreport (= Bericht) formulieren kann, muss schweigen.</p> </body> </html>
Und dann braucht es den „Kleister“, der die Arbeit macht und alles zusammenpackt. Nennen wir es untisparser.sh und legen es in das passende Verzeichnis auf dem Server:
#!/bin/bash
# UntisParser
#
# Parse HTML Export Files created by WebUntis
# do "e pluribus unum" with a Bash script
# throw the output into a Moodle file repository
# and link the output from inside a Moodle Courseroom
#
# You need the pup executable from https://github.com/ericchiang/pup
#
# (C) dowel
# License: CC BY SA https://creativecommons.org/licenses/by-sa/4.0/deed.de
# Date: 2018-08-23
# Version 0.2
# ####
# def of some base vars
RUNT=$(date '+%Y-%m-%d %H:%M:%S')
RUNF="20 Minuten" # set this in cronjob
RELOAD="120 Sekunden" # see head_filename
WORKDIR="/path/untisparser"
PUPPATH="/path/bin"
HEAD_FILENAME="kopf.html" # asumed to be in workdir
FOOT_FILENAME="fuss.html" # asumed to be in workdir
OUTPUT_PATH="/path/moodledata/repository/anzeigebretter" # set this to your Moodle file repository
OUTPUT_FILENAME="output.html"
# headline def
LUL1H="Anzeige Lehrer/innen Teil 1 Linke Seite (Heute?)"
LUL2H="Anzeige Lehrer/innen Teil 2 Rechte Seite (Morgen?)"
SUS1H="Anzeige Schüler/innen Teil 1 Linke Seite (Heute?)"
SUS2H="Anzeige Schüler/innen Teil 2 Rechte Seite (Morgen?)"
# path stuff
# Where are the Untis files in the workdir?
L_SUBDIR="$WORKDIR/Lehrerbrett"
S_SUBDIR="$WORKDIR/Schuelerbrett"
# How many of the suckers are there?
COUNT_LF1=$(/usr/bin/find $L_SUBDIR/f1 -maxdepth 1 -name '*.htm' | /usr/bin/wc -l)
COUNT_LF2=$(/usr/bin/find $L_SUBDIR/f2 -maxdepth 1 -name '*.htm' | /usr/bin/wc -l)
COUNT_SF1=$(/usr/bin/find $S_SUBDIR/f1 -maxdepth 1 -name '*.htm' | /usr/bin/wc -l)
COUNT_SF2=$(/usr/bin/find $S_SUBDIR/f2 -maxdepth 1 -name '*.htm' | /usr/bin/wc -l)
# Warning jabber because we do not know how many old files there are
# and if cleaner.script has worked the way it should have
# we asume that it failed
WARNMESS="<p>
--------------------------------------------------------------------------------------<br>
Stand: $RUNT | Beachte: Das Skript läuft nur alle $RUNF und die Seite wird nach $RELOAD neu geladen!<br>
Achte auf das Datum. Es kann sein, dass ab hier alte Dateien ausgelesen werden. Wenn das so ist, dann den Rest ignorieren.</br>
<a href=\"#top\">Ganz nach oben</a> || LuL: <a href=\"#lul1\">Links</a> | <a href=\"#lul2\">Rechts</a> || SuS <a href=\"#sus1\">Links</a> | <a href=\"#sus2\">Rechts</a>
</p>"
# create empty output file and fill it with html head and some simple navigation stuff
/bin/cat $WORKDIR/$HEAD_FILENAME > $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<id=\"top\">" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<p><em>Links</em> ist meist <em>Heute</em> und <em>Rechts</em> ist meist <em>Morgen</em> - aber nicht immer.</p>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<p>Anzeige Lehrer/innen: <a href=\"#lul1\">Links</a> | <a href=\"#lul2\">Rechts</a></p>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<p>Anzeige Schüler/innen: <a href=\"#sus1\">Links</a> | <a href=\"#sus2\">Rechts</a></p>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<p>Stand: $RUNT | Beachte: Das Skript läuft nur alle $RUNF!</p>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<p></p>">> $OUTPUT_PATH/$OUTPUT_FILENAME
# ticker export
if [ -f $L_SUBDIR/ticker.htm ]
then
/bin/echo "<h4>L Ticker</h4>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
$PUPPATH/pup --charset iso-8859-1 -f $L_SUBDIR/ticker.htm 'marquee text{}' >> $OUTPUT_PATH/$OUTPUT_FILENAME
fi
if [ -f $S_SUBDIR/ticker.htm ]
then
/bin/echo "<h4>S Ticker</h4>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
$PUPPATH/pup --charset iso-8859-1 -f $S_SUBDIR/ticker.htm 'marquee text{}' >> $OUTPUT_PATH/$OUTPUT_FILENAME
fi
# Create teacher part of output file
/bin/echo "<h2 id=\"lul1\">$LUL1H</h2>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
COUNT=1
MAXCOUNT=1
let MAXCOUNT=COUNT_LF1+1
# teacher links
while [ $COUNT -lt $MAXCOUNT ] ; do
# padding
NUM=$(printf %03d $COUNT)
# Date extract to button
/bin/echo "<button class=\"accordion\">" >> $OUTPUT_PATH/$OUTPUT_FILENAME
$PUPPATH/pup --charset iso-8859-1 -f $L_SUBDIR/f1/subst_$NUM.htm 'div.mon_title' >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "</button>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<div class=\"panel\">" >> $OUTPUT_PATH/$OUTPUT_FILENAME
# Headline is set to H4
/bin/echo "<h4>Lehrer/innen</h4>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<p></p>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
# Table extraction
$PUPPATH/pup --charset iso-8859-1 -f $L_SUBDIR/f1/subst_$NUM.htm 'table' >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "</div>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
# Warning
/bin/echo $WARNMESS >> $OUTPUT_PATH/$OUTPUT_FILENAME
let COUNT=COUNT+1
done
# Reset for second part of LuL
/bin/echo "<h2 id=\"lul2\">$LUL2H</h2>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
COUNT=1
MAXCOUNT=1
let MAXCOUNT=COUNT_LF2+1
# teacher rechts
while [ $COUNT -lt $MAXCOUNT ] ; do
# padding
NUM=$(printf %03d $COUNT)
# Date extract to button
/bin/echo "<button class=\"accordion\">" >> $OUTPUT_PATH/$OUTPUT_FILENAME
$PUPPATH/pup --charset iso-8859-1 -f $L_SUBDIR/f2/subst_$NUM.htm 'div.mon_title' >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "</button>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<div class=\"panel\">" >> $OUTPUT_PATH/$OUTPUT_FILENAME
# Headline is set to H4
/bin/echo "<h4>Lehrer/innen</h4>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<p></p>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
# Table extraction
$PUPPATH/pup --charset iso-8859-1 -f $L_SUBDIR/f2/subst_$NUM.htm 'table' >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "</div>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
# Warning
/bin/echo $WARNMESS >> $OUTPUT_PATH/$OUTPUT_FILENAME
let COUNT=COUNT+1
done
# Create pupil part of output file
/bin/echo "<h2 id=\"sus1\">$SUS1H</H2>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
COUNT=1
MAXCOUNT=1
let MAXCOUNT=COUNT_SF1+1
# pupil links
while [ $COUNT -lt $MAXCOUNT ] ; do
# padding
NUM=$(printf %03d $COUNT)
# Date extract to button
/bin/echo "<button class=\"accordion\">" >> $OUTPUT_PATH/$OUTPUT_FILENAME
$PUPPATH/pup --charset iso-8859-1 -f $S_SUBDIR/f1/subst_$NUM.htm 'div.mon_title' >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "</button>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<div class=\"panel\">" >> $OUTPUT_PATH/$OUTPUT_FILENAME
# Headline is set to H4
/bin/echo "<h4>Schüler/innen</h4>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<p></p>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
# Table extraction
$PUPPATH/pup --charset iso-8859-1 -f $S_SUBDIR/f1/subst_$NUM.htm 'table' >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "</div>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
# Warning
/bin/echo $WARNMESS >> $OUTPUT_PATH/$OUTPUT_FILENAME
let COUNT=COUNT+1
done
# Reset for second part of SuS
/bin/echo "<h2 id=\"sus2\">$SUS2H</h2>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
COUNT=1
MAXCOUNT=1
let MAXCOUNT=COUNT_SF2+1
# pupil rechts
while [ $COUNT -lt $MAXCOUNT ] ; do
# padding
NUM=$(printf %03d $COUNT)
# Date extract to button
/bin/echo "<button class=\"accordion\">" >> $OUTPUT_PATH/$OUTPUT_FILENAME
$PUPPATH/pup --charset iso-8859-1 -f $S_SUBDIR/f2/subst_$NUM.htm 'div.mon_title' >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "</button>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<div class=\"panel\">" >> $OUTPUT_PATH/$OUTPUT_FILENAME
# Headline is set to H3
/bin/echo "<h4>Schüler/innen</h4>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "<p></p>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
# Table extraction
$PUPPATH/pup --charset iso-8859-1 -f $S_SUBDIR/f2/subst_$NUM.htm 'table' >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/echo "</div>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
# Warning
/bin/echo $WARNMESS >> $OUTPUT_PATH/$OUTPUT_FILENAME
let COUNT=COUNT+1
done
# create footer
/bin/echo "<p></p>" >> $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/cat $WORKDIR/$FOOT_FILENAME >> $OUTPUT_PATH/$OUTPUT_FILENAME
# cleanup
/bin/chown www-data.www-data $OUTPUT_PATH/$OUTPUT_FILENAME
/bin/chmod 2750 $OUTPUT_PATH/$OUTPUT_FILENAME
# and we are done
exit 0
Cron ruft das Skript alle 20 Minuten auf. Schöner wäre natürlich, wenn das Skript nur liefe, wenn sich was ändert im WebDavs Share. Aber inotify und Freunde sind auch nicht ohne. So ist es simpel und scheint zu funktionieren, ohne viel Ressourcen zu fressen.
Update 23.08
Einige Fehler im Skript (meist die vergessenenen \ vor den „) behoben und mit Hilfe von JavaScript mehr Übersichtlichkeit im Output erzeugt.