Um viele Laptops möglichst zügig mit einem Betriebssystem versorgen zu können, habe ich eine „Debian Installbox“ erzeugt. Diese basiert auf
https://salsa.debian.org/installer-team/netboot-assistant
und der Dank geht somit an andi für das Konzept, die Skripte und seine Unterstützung.
Meine eigenen Konfigurationsdateien habe ich ins Git gelegt:
https://codeberg.org/dowel/installbox
Eine fertige VM für Virtualbox kann mensch hier herunterladen:
https://cloud.kvfg.de/index.php/s/aXtJQxKccPCm8kX
Ein paar Erläuterungen dazu:
Host
Den Hostrechner mit zwei Netzwerkkarten versorgen. Die „nach Außen“ / Richtung Internet zeigende Netzwerkkarte sollte die langsamere der beiden sein. Nach „innen“ und damit in Richtung der zu installierenden Maschinen das schnellste nehmen, was rumliegt.
Die VM unter Debian Buster braucht nicht viel – die voreingestellten 4GB und 2 CPUs sollten reichen. Vermutlich reicht auch die Hälfte – die VM hat ja fast nix zu tun, außer Steuerbefehle zu schicken und Dateien auszuteilen. Der Host sollte das doppelte der VM an Ressourcen aufweisen. Hier klappt das auf Rechnern der „Isny-Klasse“ (Core i3 mit 8 GB RAM und SSD) ganz flott – so als Orientierung.
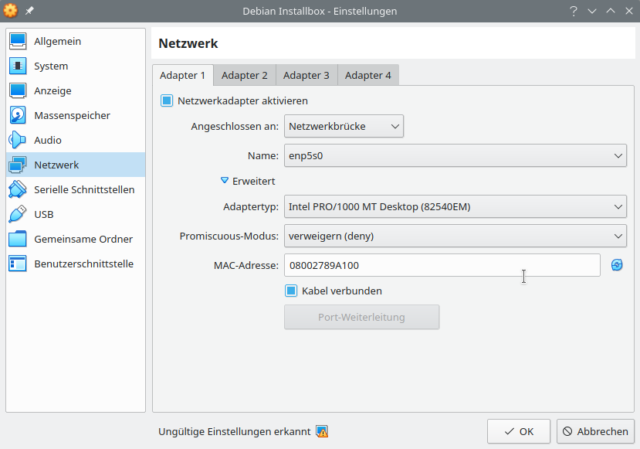
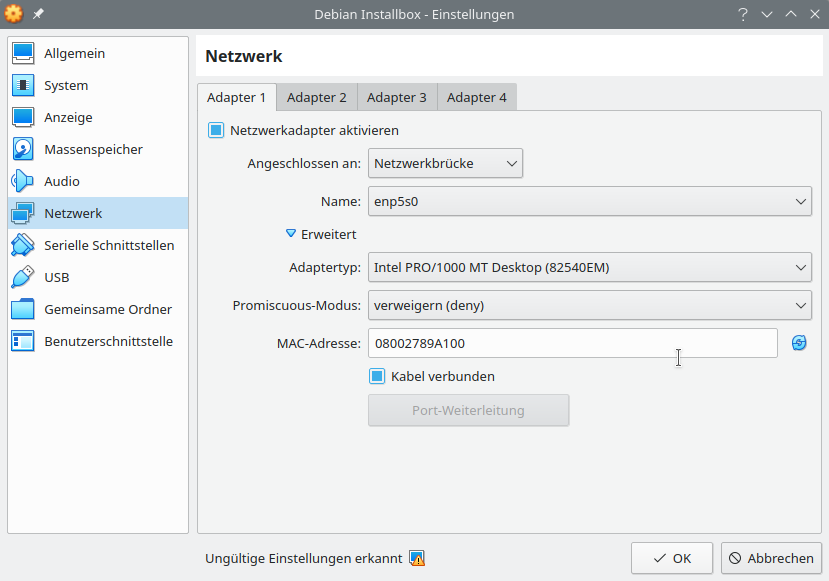
Adapter 1 zeigt in Richtung Internet und ist im Auslieferungszustand vermutlich noch als Bridge konfiguriert, weil das in meinem lokalen Netz praktischer war. Das Interface darf ruhig NATen. Im Bild oben ist das nicht so, weil ich dann vom VM-Host via SSH einfacher auf die VM komme.
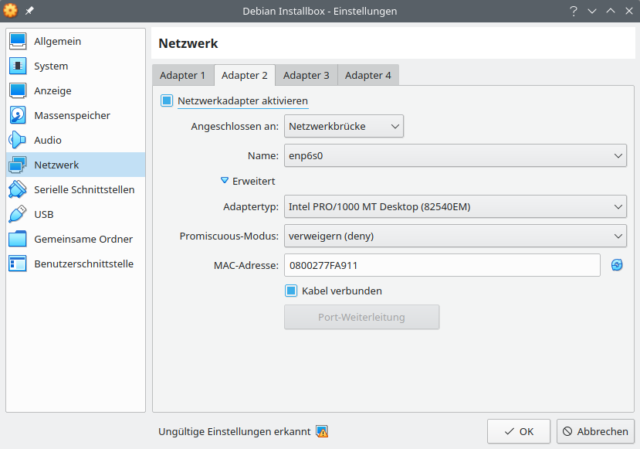
Adapter 2 zeigt in Richtung der zu installierenden Maschinen und muss deswegen eine Netzwerkbrücke direkt auf das Interface im Host sein. Hier in der VM die Einstellungen in /etc/network/interfaces nur befummeln, wenn man die Folgen abschätzen kann – also dazu bereit ist, die Konfiguration zu überarbeiten. Voreingestellt ist hier die IP 192.168.0.10. Da fährt dann auch der TFTP-Server hoch und lauscht der dnsmasq auf Anfragen.
Am Host selbst hatte ich für diese zweite Karte keine IP gesetzt, was unter Arch gut funktionierte. Unter Debian funktionierte das überhaupt nicht. Da musste ich auf dem Host dem Interface eine 192.168.0.1 statisch verpassen, erst dann konnte die VM dort bridgen.
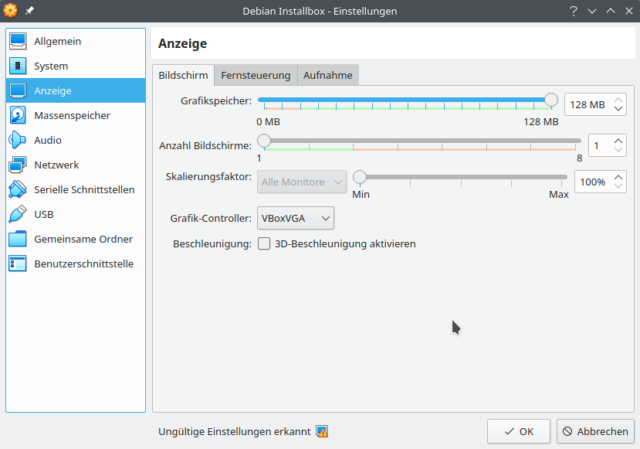
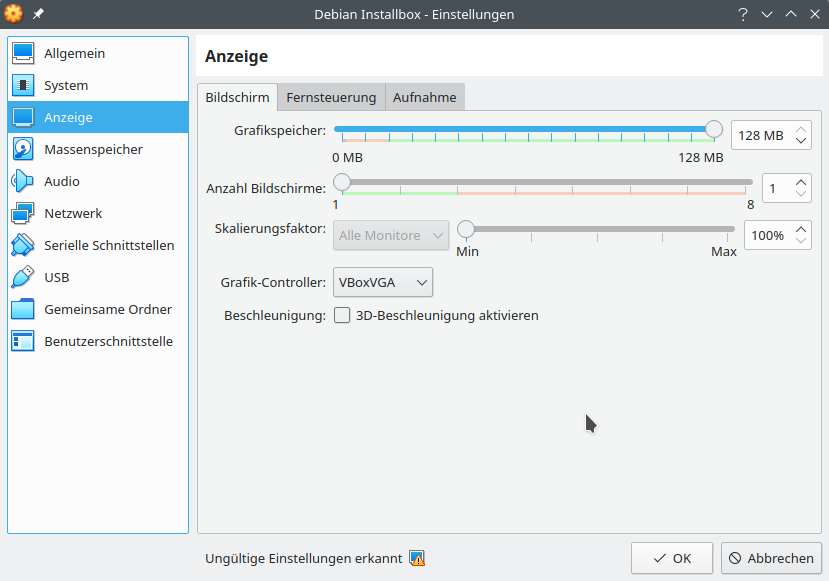
Dann noch eine Anmerkung zum Grafik-Controller: VBox will da inzwischen VMSVGA haben. Das führt in der Debian-VM hier (unter Arch) jedoch dazu, dass diese alle paar Sekunden eine Denkpause in der GUI einlegt. Mit VBoxVGA flutscht es in der VM weitaus besser. Muss man ausprobieren – tun sollte beides.
VM
Usermanagement
Es sind zwei Benutzer eingerichtet – installbox als Arbeitskonto (Passwort: muster) und kvfg (Passwort: kvfg) für die Erzeugung eines hübschen Homeverzeichnisses für die SuS, das dann auf die Laptops mit ausgerollt wird und somit schon alle sinnigen Einstellungen mitbringt. Da müsst ihr Euch halt einen eigenen backen – das Schulkürzel bietet sich als Benutzername wie auch als Passwort an.
Also: Als kvfg anmelden und alle Einstellungen so vornehmen, wie sie später die SuS an den Laptops vorfinden sollen. Z.B. kann hier das hässliche XFCE-Debian-Theme überarbeitet werden. Ich habe dann noch in Firefox ublock und decentraleyes installiert, die Suchmaschinenliste überarbeitet, Bookmarks eingefügt, die Startseite angepasst und auch Libreoffice für den Einsatz in den Fächern Deutsch, Englisch, Französisch und Spanisch inklusive Beispieldateien vorbereitet. Weiter habe ich Nextcloud „halb installiert“, damit den SuS das auch auffällt, wie sie von zu Hause aus geschickt arbeiten könnten. Dazu kommt – seit der letzten Version – auch ein Skript, das die Verbindung mit dem Schulnetzwerk herstellt (WLAN, Servermounts), sofern die SuS mal in der Schule arbeiten. So Sachen eben, die den Alltag für die SuS erleichtern.
Sobald das alles nach Wunsch aussieht ausloggen und als installbox wieder anmelden. Von diesem Konto aus als root das Homeverzeichnis von kvfg komplett in ein TAR packen. Das Skript build-skel.sh im Rootverzeichnis hilft dabei.
Die Laptops holen sich im Zuge der Installation das TAR-Archiv und entpacken das auf dem Laptop nach /home/kvfg, womit die Einstellungen auf den Geräten wie gewünscht gesetzt sind.
Wer sich einen eigenen Benutzer für die Schule gebacken hat, sollte also die Pfade und Namen in der preseed.cfg daraufhin überprüfen.
Hints
Die VM ist mit einem Apt-Cacher NG versorgt, der die gesamte Installation Stand 13.08.2020 10:00 Uhr auch offline abwickeln kann. Ihr könnt in der VM unter http://localhost:3142 nachsehen, wie viel an Download aus dem Netz ihr schon gespart habt – und außerdem geht es so einfach total flott.
In Zeile 81 hinter
d-i pkgsel/include string
der preseed.cfg sind die Pakete aufgeführt, die nachinstalliert werden. Da lassen sich leicht weitere ergänzen. Ich hab hier z.B. Gimp, VLC, Okular und Gwenview sowie Kate mit eingetragen, weil ich diese selbst gerne nutze – und weil sie auf den Clients in der Schule auch da sind. Dazu kamen dann noch Cheese für einen Test der Webcam und Nextcloud-Desktop für die Verbindung mit der Schulcloud usw usw usw …
Releases
2020-08-13
Initial release
2020-08-14
Paketliste ergänzt (Druckmöglichkeit), Splash-Screen, Softwarecenter
2020-08-17
Paketliste ergänzt (simple-scan), ublock im Firefox-ESR für die BBB Domains auf lehrerfortbildung-bw.de und die schulischen Domains deaktiviert
2020-08-18
KISS: Die Druckerpakete machen vermutlich keinen Sinn. Wenn die SuS keine Geräte haben und deswegen einen Laptop von der Schule erhalten, dann haben diese aller Wahrscheinlichkeit nach auch keinen Drucker rumstehen – und wenn doch, dann lernen sie was bei der Nachinstallation. Synaptics-Touchpad-Treiber kamen noch dazu – und die Repos wurden freundlicher eingestellt (contrib, non-free hinzugefügt).
2020-08-20
Das XFCE-Batteriestatus Icon hat noch gefehlt. Weiter habe ich, um den Überblick zu behalten, etckeeper und git auf den Laptops installiert [1]. So kann bei Tests vor Ort besser abgeschätzt werden, welche Anpassungen noch fehlen (z.B. Netzwerkverbindungen).
Die Verbindung mit dem Schulnetz wird nun via WPA2-Enterprise hergestellt. Deswegen wird in der Downloadversion der VM eine weitere Datei mit ausgerollt:
/var/lib/tftpboot/d-i/buster/schueler.nmconnection
In dieser sind die Credentials für die Verbindung mit dem Schulnetz „schueler“ mit drin (in der Downloadversion der VM nicht wirklich – aber den Teil muss mensch eh selbst an die Gegebenheiten in der Schule vor Ort anpassen).
Damit diese Configdatei an Ort und Stelle auf den Laptops ankommt, wurde dann die preseed.cfg überarbeitet, was wiederum im Git auf Codeberg (Link siehe oben) zu finden ist.
Damit evtl. Änderungen schnell eingepflegt werden können, die schueler.nmconnection in der VM nach /root legen. Dort liegt auch das Skriptchen build-skel.sh, das dann das Homeverzeichnis zusammen mit dieser Datei packt.
2020-08-24
Die VM hat nun Skripte an Bord, die auf den Laptops die Einrichtung individueller Verbindungen mit dem Schulnetzwerk (WPA2-Enterprise) unterstützen – inklusive mount der Servershares. Der Würgaround vom 20.08 mit einem Xtra-User ist somit nicht mehr nötig.
2020-08-25
Gut, wenn man noch einmal drüber schläft. Ich hatte die cifs-utils in der preseed.cfg vergessen.
Systempflege
2021-06-25
Fährt mensch die Installbox nach einigen Wochen / Monaten erneut hoch, dann passt der Kernel nicht mehr und die Fehlermeldung
Es wurden keine Kernel-Module gefunden. Dies liegt vermutlich an einem Unterschied zwischen dem hier verwendeten Kernel des Installers und dem Kernel, der im Debian-Archiv verfügbar ist […]
taucht auf. Hier scheint das folgende Vorgehen geholfen zu haben:
- Alle Pakete aus dem Apt-Cacher NG löschen
- lokales Update der Installbox durchführen
- di-netboot-assistant frisch machen:
di-netboot-assistant purge stable
di-netboot-assistant install stable
di-netboot-assistant fw-toggle stable
di-netboot-assistant rebuild-grub
di-netboot-assistant rebuild-menu
Irgendwo auf dem Weg zum Glück bog ich dabei falsch ab und erhielt bei der Partitionierung die Meldung, dass kein Root-Dateisystem angegeben worden sei. Ein Reboot der Installbox scheint das aber erledigt zu haben. Jetzt läuft die Installation wieder durch. Ursächlich ist wohl eher der Client selbst, dessen Festplatte nicht erkannt wurde. Hier half bei weiteren Versuchen ein Strg-Alt-F1 und dann die Auswahl von „Festplatten erkennen“. Klappt das, dann läuft die Installation auf Basis der preseed.cfg danach weiter.
Da ich jetzt am Spielen bin habe ich noch meine auf Debian 10 laufende Clonezilla VM ins oben angegebene Repo gelegt. Kurzbeschreibung:
Adapter 1 mit 080027358D91 zeigt in Richtung Internet (NAT)
Adapter 2 mit 080027129480 zeigt in Richtung Clients (Bridged)
# Benutzerkonten
root: muster
konto: muster
Adapter 1 wird vom NetworkManager verwaltet. Adapter 2 wird von ifupdown mit 192.168.0.10 versorgt. Auf dem Desktop befindet sich eine TXT Datei mit den wichtigsten Einstellungen und Befehlen. Clonezilla läuft hier so, dass Images erstellt und wieder ausgerollt werden können. Schon enthalten ist das Image aus der Installbox in /home/partimg/ … und das bau ich nun weiter aus und um.
2021-06-26 I
firmware-iwlwifi wird nun bei der Installation via Installbox auf den T450ern explizit benötigt. Das habe ich ergänzt – auch in der preseed.cfg auf Codeberg. Das Installbox Image ist aktualisiert und frisch hochgeladen.
Die Clonezilla-Server Variante enthält nun zwei Images: Einmal das, was die Installbox auswirft (XFCE als Desktop) und zusätzlich noch ein Image mit KDE mit den folgenden, zusätzlich installierten und schon vorkonfigurierten Paketen:
kde-full breeze-gtk-theme thunderbird thunderbird-l10n-de keepassxc inkscape youtube-dl flatpak gnome-software-plugin-flatpak
2021-06-26 II
Die Installbox bietet nun beim Boot des Clients zwei Installationsoptionen an: Bullseye und Buster jeweils mit XFCE als Desktop.
Die Dokumentation dazu auf Codeberg ist aktualisiert.
In der nächsten Pflegestufe kommt der Clonezillaserver dran – mit XFCE und KDE Desktop für Bullseye.